引言:多智能体系统的存在必要性
在讨论多智能体系统的具体实现之前,我们必须首先回答一个根本性问题:多智能体系统是否应该存在?
这个问题的核心在于:多智能体是否只是一个阶段性的解决方案——即当单个语言模型足够强大时,多智能体系统就会变得多余?如果答案是肯定的,那么我们就没有必要在这个方向上投入过多精力。
单模型性能增长的极限思考
即使我们假设单个模型能够无限接近AGI,甚至达到超人智能水平,也存在一些根本性的结构约束:

认知架构的约束: 无论模型多么智能,单一实例仍然只能维持一个思考流程。这类似于即使是天才,也无法同时从多个完全独立的角度思考同一个问题。
并行处理的需求: 复杂任务往往需要多个专业领域的并行分析。一个模型无论多强,也无法真正实现并行思考——它只能快速切换,而不是真正的同时处理。
上下文隔离的价值: 即使上下文窗口可以无限扩大,在处理复杂任务时,我们仍然需要维护多个独立的思考空间,避免不同领域的信息相互干扰。
结论:多智能体的长期价值
基于这些分析,我们认为多智能体系统不是一个过渡方案,而是具有长期价值的架构选择。它解决的不是智能水平问题,而是认知架构问题。
我们的核心论点是:一个模型,多个对话,多个上下文窗口。这种架构即使在模型达到超人智能水平时仍然是必要的。
本文将从四个核心洞察出发,系统性地分析多智能体系统的本质:
- 结构性约束与多上下文窗口的必要性
- 搜索即压缩,压缩即智能的AI本质
- Token消耗作为智能系统的核心指标
- 管理学视角:个体能力vs组织效能的根本差异
核心洞察一:结构性约束与多上下文窗口的必要性
单智能体的根本性约束
单智能体的局限性不在于智能水平,而在于其结构性约束。这种约束体现在三个层面:
认知约束: 单一视角的思维模式
- 即使是超级智能,单智能体仍然只能从一个角度思考问题
- 人类历史上最聪明的个体也会有认知盲区,这是视角单一性造成的
处理约束: 线性的信息处理方式
- 必须按顺序处理信息,无法真正并行思考
- 深度思考和广度探索之间存在天然冲突
上下文约束: 有限的工作记忆空间
- 无论上下文窗口如何扩大,仍然是有限的
- 复杂问题往往需要多个独立的思考空间
多上下文窗口的架构优势
多智能体系统的核心不是使用多个不同的模型,而是使用同一个模型的多个实例,每个实例维护独立的上下文窗口:
并行认知处理:
- 每个上下文窗口可以从不同角度同时思考同一个问题
- 类似于人类团队中的专家分工,但速度更快、协调更精确
专注领域分离:
- 技术分析的上下文不会被市场信息"污染"
- 每个思考过程保持纯粹性和深度
动态资源分配:
- 可以根据问题复杂度动态增加或减少上下文窗口数量
- 实现了计算资源的灵活配置
核心洞察二:搜索即压缩,压缩即智能的AI本质
搜索为什么等于压缩
这一观点看似抽象,实际上揭示了AI智能的根本机制。让我们深入分析为什么这个等式成立:
信息理论基础: 搜索的本质是在庞大的信息空间中寻找相关信息。这个过程必然涉及信息的筛选、排序和提炼,而这正是压缩的定义——保留最重要的信息,丢弃冗余内容。
认知科学视角: 人类智能的核心机制就是模式识别和抽象能力。我们能够从大量感知信息中提取出关键模式,这种提取过程就是压缩。AI系统的学习过程同样如此——从训练数据中压缩出可泛化的模式。
实际案例分析: 当AI进行文献检索时,它需要:
- 从数千篇论文中识别相关内容(搜索)
- 提取关键信息点(压缩)
- 形成连贯的理解(智能表现)
这三个步骤是一体的,搜索和压缩共同构成了智能行为。
多智能体系统中的分布式压缩
多智能体系统实现了分布式的智能压缩机制:
并行搜索压缩:
- 每个子智能体在其专业领域内进行深度搜索和压缩
- 避免了单一智能体的认知瓶颈
层次化信息提炼:
- 子智能体:原始信息 → 领域洞察(第一层压缩)
- 主智能体:领域洞察 → 综合结论(第二层压缩)
质量保证机制:
- 通过多个独立的压缩过程相互验证
- 降低了单一压缩过程的错误风险
例如,在研究市场趋势时:
- 汽车行业智能体:处理500篇汽车相关文章 → 5个关键趋势
- 医疗行业智能体:处理300篇医疗文章 → 4个重要发现
- 技术行业智能体:处理400篇技术文章 → 6个核心变化
- 主智能体:整合15个洞察 → 3个跨行业的战略建议
这种分布式压缩机制的效率远超单智能体的线性处理。
核心洞察三:Token消耗作为智能系统的核心指标
Token消耗的本质意义
这是一个极其重要但被严重低估的观点:Token消耗量是智能系统最重要的指标。这不仅仅是成本考虑,更是对智能本质的深刻理解。
智能即计算密度: 复杂问题的解决需要大量的认知处理。在AI系统中,这种处理直接对应于Token的消耗。高质量的思考必然需要更多的Token来支撑。
思考质量与Token使用的正相关: Anthropic的研究数据支持这一观点:Token使用量解释了80%的性能差异。这不是偶然现象,而是反映了深层规律。
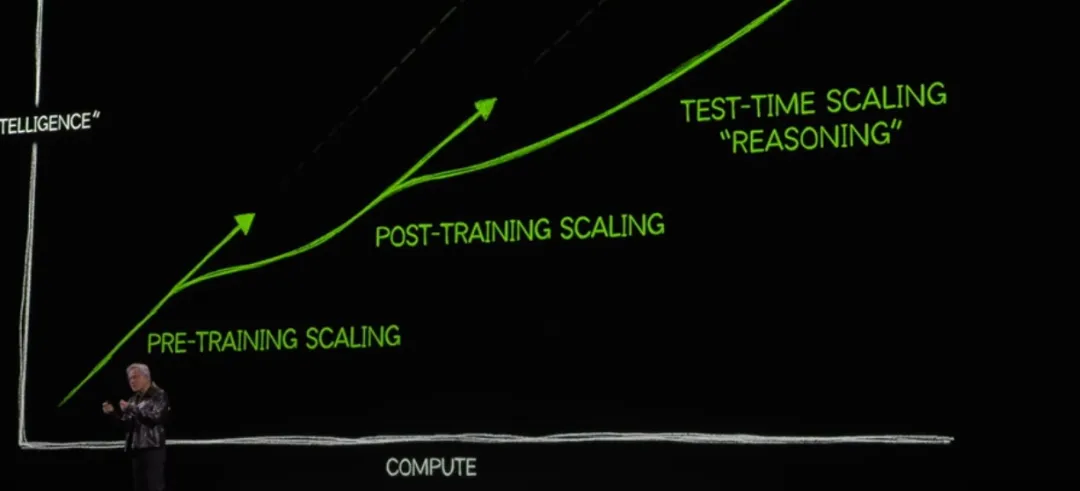
从预训练扩展到推理扩展的转变: 如上图所示,AI发展正从依赖更大模型转向投入更多推理计算。这意味着未来的AI竞争将集中在谁能更有效地消耗Token来解决复杂问题。
多智能体系统的Token扩展优势
无上限的Token容量: 单智能体受限于单一上下文窗口的Token预算,而多智能体系统通过分布式架构实现了几乎无限的Token扩展能力。
并行Token投入:
- 单智能体:串行消耗Token,存在处理瓶颈
- 多智能体:并行消耗Token,充分利用计算资源
成本效益的战略考量: 根据Anthropic的数据:
- 普通聊天:基础Token消耗
- 单智能体应用:约4倍Token消耗
- 多智能体系统:约15倍Token消耗
这种成本结构表面上看似昂贵,实际上是智能密度的体现。对于高价值问题,15倍的Token投入往往能够带来远超15倍的价值回报。
Token消耗的优化策略:
- 任务复杂度评估:简单任务使用单智能体,复杂任务启动多智能体
- 动态资源分配:根据中间结果调整Token投入
- 价值导向决策:只对足够重要的问题投入大量Token
核心洞察四:管理学视角——个体能力vs组织效能的根本差异
大模型进化:培养超级个体的路径
当前AI领域的主流发展路径专注于单体模型能力的极限提升——从GPT-3到GPT-4,从Claude-1到Claude-3,我们见证了单个模型在各项任务上的惊人突破。这本质上是一条培养超级个体的路径:
超级个体的特征:
- 知识储备接近人类总和
- 推理能力超越绝大多数专家
- 处理速度远超人类
然而,正如现实世界中最优秀的个体专家一样,即使是超级智能的单体也存在不可突破的上限。
多智能体系统:组织管理的AI实现
多智能体系统解决的是一个根本不同的问题——组织效能问题。它不是在追求更强的个体,而是在探索如何通过有效的组织机制,实现"1+1>2"的协同效应。
管理学的核心洞察在AI中的体现:
分工协作的力量: 即使是相对"平庸"的智能体,通过合理的分工和协作机制,也能在特定领域发挥出超过单个超级智能体的效果。正如一个由普通专家组成的研究团队,往往能够产出超过单个天才学者的成果。
并行处理的组织优势:
- 单个超级个体:串行处理,再强也只能同时专注一个问题
- 多智能体组织:真正的并行处理,多个问题同时推进
知识领域的隔离与专精: 在复杂项目中,不同领域的知识混合往往会产生干扰。多智能体系统通过"部门化"的方式,让每个智能体在其专业领域内保持纯粹的思考环境。
现实世界的管理学类比
企业组织的启示:
- 个体能力提升:培训员工,提升单人技能(类比大模型进化)
- 组织效能优化:设计流程,建立协作机制(类比多智能体系统)
最成功的组织往往同时在这两个维度发力,但它们解决的是不同层面的问题。
体育团队的案例: 一支篮球队的成功不仅取决于是否有超级明星(超级个体),更依赖于:
- 位置分工的合理性
- 战术配合的默契度
- 不同角色的有机协调
这正是多智能体系统要解决的核心问题。
两种路径的互补性
并非竞争关系: 大模型进化与多智能体系统不是零和游戏。现实中最有效的解决方案往往是:
- 基础能力强的个体(强大的基础模型)
- 加上高效的组织机制(智能的多智能体协调)
战略意义的重新定义: 这一视角帮助我们理解为什么即使在模型能力不断提升的未来,多智能体系统仍然具有不可替代的价值——它们解决的是组织层面的效能问题,而非个体层面的能力问题。
对AI系统设计的启示:
- 不要试图用多智能体系统解决单体能力不足的问题
- 专注于设计能够充分发挥协同效应的组织架构
- 重视"管理层"智能体的设计,它们负责协调和决策
技术实现:多上下文窗口的工程化
基于新观点的系统设计
基于前述四个核心洞察,多智能体系统的设计应该遵循以下原则:
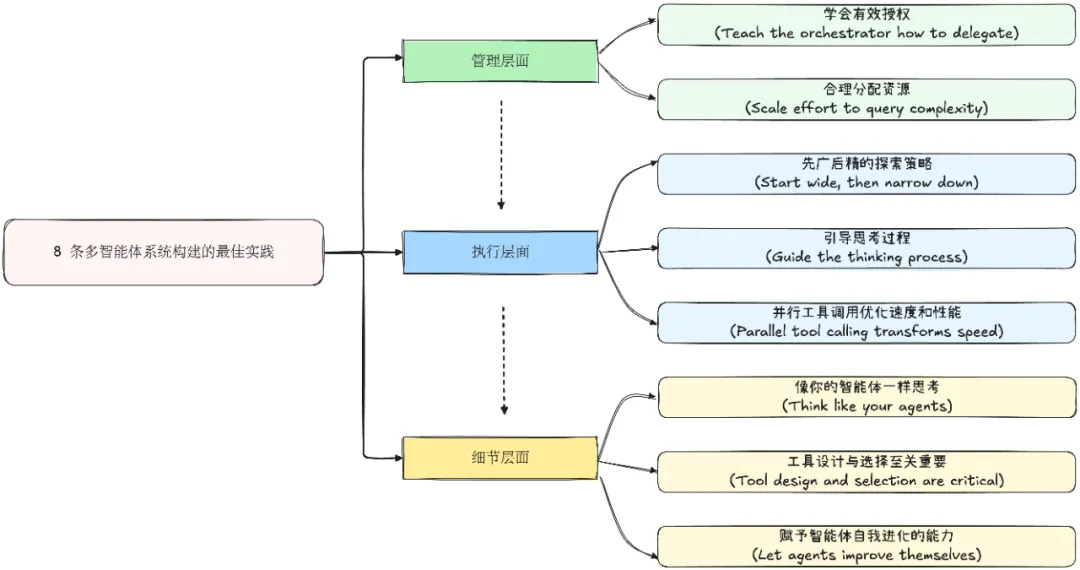
架构设计原则:
- 统一模型,多实例部署:使用同一个高质量模型的多个实例
- 独立上下文管理:每个实例维护专用的上下文窗口
- Token预算分配:根据任务价值合理分配Token资源
实现层面的关键技术:
1. 智能路由器(Intelligent Router)
- 评估问题复杂度,决定启动几个上下文窗口
- 动态分配专业领域,避免重复劳动
- 实时监控Token消耗,优化资源配置
2. 上下文窗口管理器(Context Manager)
- 为每个智能体实例分配独立的工作空间
- 实现跨窗口的信息传递机制
- 管理长期记忆和短期工作记忆
3. 压缩协调器(Compression Coordinator)
- 收集各个上下文窗口的压缩结果
- 进行二次压缩和信息整合
- 确保最终输出的一致性和完整性
评估与优化策略
评估维度重新定义:
- Token效率:单位Token产生的价值
- 压缩质量:信息提炼的准确性和完整性
- 并行效果:多上下文协作的协同效应
优化策略:
- 启发式Token分配:根据问题类型预设Token预算
- 动态调整机制:基于中间结果调整资源投入
- 质量监控系统:实时评估每个上下文窗口的产出质量
结论:面向Token消耗优化的AI系统设计
通过这三个核心洞察的分析,我们可以得出一个重要结论:多智能体系统不是对单智能体的替代,而是对AI能力边界的突破。
战略意义的重新认识:
1. 共存而非竞争 单智能体继续在其擅长的领域发挥作用,多智能体系统解决单智能体结构性无法处理的复杂问题。这是能力互补,不是技术替代。
2. Token消耗作为核心竞争力 未来AI系统的竞争将不再仅仅是模型参数的竞争,而是谁能更智能地消耗Token,在相同的计算预算下产生更高质量的输出。
3. 压缩能力决定智能上限 AI系统的智能水平最终由其压缩能力决定——能够从多大的信息空间中提取多少有用信息。多智能体系统通过分布式压缩实现了质的突破。
对从业者的启示:
- 重新评估成本模型:Token消耗不是成本,而是智能投资
- 设计Token优化的架构:系统设计的核心目标是最大化Token使用效率
- 建立多层次压缩能力:培养从原始信息到深层洞察的多层次提炼能力
这一转变反映了AI系统发展的新趋势:从追求单体智能的极限,转向设计能够高效消耗计算资源、实现分布式智能压缩的系统架构。这不仅是技术演进,更是我们对智能本质理解的深化。